The following series of posts reflects my experiences as a first-time explorer of various pieces of learning analytics and data mining software applications. The purpose of these explorations is for me to gain a better understanding of the current palette of tools and visualizations that may possibly support my own research in learning analytics within the context of a face-to-face/blended collaborative learning environment in secondary science.
LightSide is an open-source text-mining and machine learning platform, created by the Language Technology Institute at Carnegie Mellon University. This software streamlines the process of extracting the basic features of a text (e.g. term vectors) using a point-and-click interface, making surface features and some simple natural language processing tools available to users without any programming knowledge/effort.
From the LightSide website:
Too often, machine learning is a black box. Researchers choose a set of features and a model to train, and they get an accuracy reported back to them by their scripts. If they’re lucky, they have a pipeline set up that allows them to tweak that behavior and evaluate performance changes. Actually looking at the text that’s being misclassified and thinking deeply about why an algorithm thinks it should be labeled a certain way almost never happens.
We’re changing that. We’ve developed a set of interfaces and tools over years of experience which direct you towards the instances that are being misclassified by your algorithm; which singles out features that are associated with error and misclassification; and with direct comparisons between models so that it becomes obvious what’s going right and what’s going wrong with a particular set of feature extraction and machine learning choices.
The basic workflow for LightSide is illustrated in Figure 1 below.

Figure 1 – LightSide workflow
For the purposes of this exploration, I followed the “Quickstart Tutorial” using the sample data set called “sentiment_sentences.csv”. With this dataset the input is a single sentence (extracted from reviews of popular movies), and the goal of the machine learning is to predict whether that sentence is positive or negative (“thumbs up” or “thumbs down”).
The first step was to extract a set of features from the source data. In this example the “Basic Features” extractor was selected. I then selected several metrics to use to evaluate the extracted features – specifically, “Kappa” (i.e. the discriminative ability over chance of this feature for the target annotation), “Total Hits” (i.e. the number of documents in the training set that contain this feature), and “Target Hits” (i.e. the number of documents with the target annotation containing this feature) (see Figure 2).
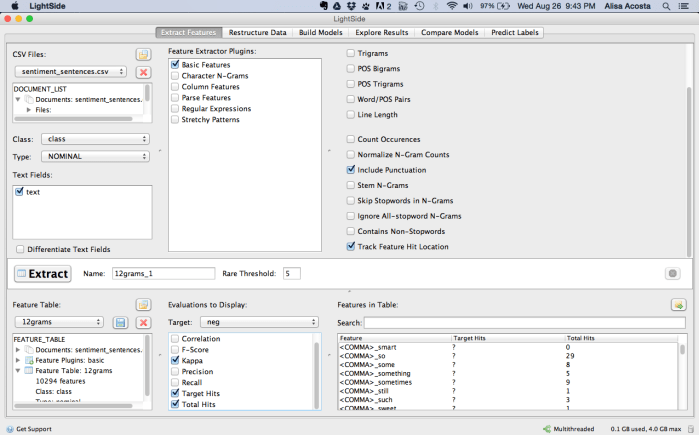 Figure 2 – The completed “Extract Features” tab for the dataset “sentiment_sentences.csv”
Figure 2 – The completed “Extract Features” tab for the dataset “sentiment_sentences.csv”
The next step was the machine learning setup – i.e. to train a model that can replicate human labels. This was accomplished under the “Build Models” tab at the top. As recommended by the tutorial, I left all the model-building configurations at their default settings and then hit the “Train” button, which produced the model shown at the bottom of Figure 3. This model had an accuracy of 77.69% and a kappa of 0.5537. As stated in the training manual:
There’s an extensive amount of optimization that can be done at this point, based on the reported performance. Understanding what to do in order to push past this baseline from your first model is one of the most imaginative and creative parts of machine learning, and makes up the bulk of the chapters of this user manual.
 Figure 3 – The trained model produced from the extracted features shown in Figure 2.
Figure 3 – The trained model produced from the extracted features shown in Figure 2.
The next step was to load new data into the model such that predictions on it can be made. For this, I loaded the sample dataset called “MovieReviews.csv” and hit the “predict” button at the bottom. As shown in Figure 4, the data set with the new prediction column appeared in the main section of the window after the prediction was complete.
 Figure 4 – Results of the prediction model
Figure 4 – Results of the prediction model
Closing Thoughts
I can see LightSide as being a useful tool for those with limited programming experience to build predictive models. Of interest is the related product, “LightSide Revision Assistant” (see video below), which supports students and teachers as they prepare written works by providing real-time formative assessment based on their writing’s clarity, development, language, and use of supporting evidence.
